
When I first started working with Kafka, I was told that Kafka Connect was the best way to ingest data into or out of Kafka. Okay, I get the part about it being good at it, but why couldn’t I simply do it myself? I could write a simple code (in any language of my choice) to read the data from the source and write it to Kafka, right?
The thing is: reliable and robust data ingestion is never simple. I’m not even talking about making it scalable and fault tolerant – doing it right is already complex.
So what Kafka Connect can give me?
Some features include:
- error handling: what to do when invalid messages are found? stop consuming? log error to stderr? include the invalid message in log for debugging? send to DLQ?
- retries: how many times to retry? how to backoff?
- data format: what data type to store/retrieve from Kafka? and what format will it have in the source/destination system?
I don’t want to give you an exhaustive list. Most of the features you can infer by checking the Kafka Connect Configuration Reference page.
Important Concepts
Without loss of generality, all descriptions below will be given from the perspective of a Sink connector (from Kafka to a destination).
Internal Message Transformations
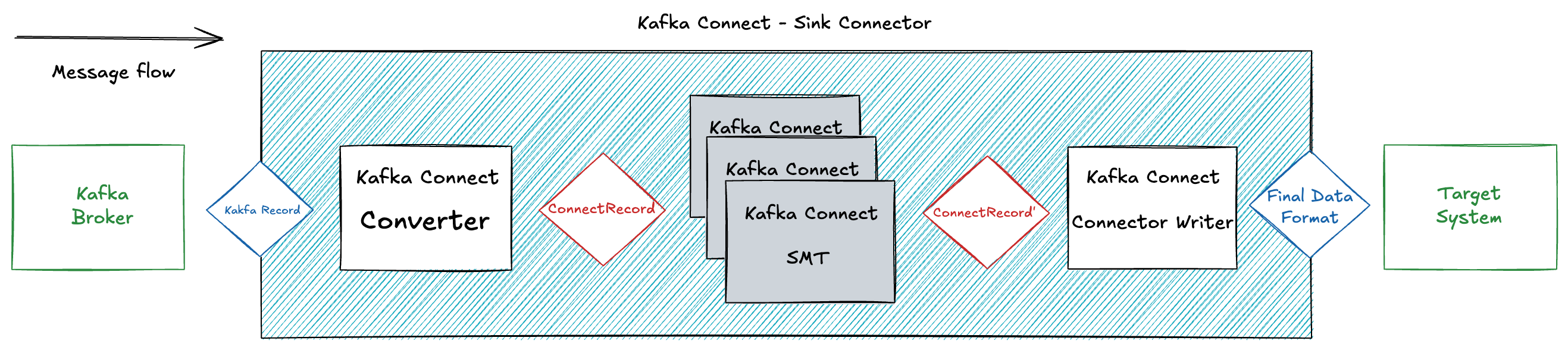
1. Kafka Record (from the topic)
- A
ConsumerRecordis read from Kafka. - It contains:
- Key (raw bytes or deserialized by key.converter)
- Value (raw bytes or deserialized by value.converter)
- Headers
- Topic / partition / offset metadata
2. Converter
- The converter is the first component that interprets the raw Kafka record’s key/value.
- Purpose: translate the raw Kafka record into a
ConnectRecord. - Happens before SMTs, so SMTs work on structured data.
- Examples:
org.apache.kafka.connect.converters.ByteArrayConverterorg.apache.kafka.connect.converters.StringConverterorg.apache.kafka.connect.json.JsonConverterorg.apache.kafka.connect.avro.AvroConverter
3. ConnectRecord
Kafka Connect itself has an internal data model for records, ConnectRecord, regardless of how the bytes look in Kafka or in the sink:
- Schema (optional) Describes the type of the value (int32, string, struct, array, map, etc.)
- Value The actual data, typed according to the schema.
- Headers Key–value metadata.
- Key
- Topic / partition / offset
By keeping an internal format, Kafka Connect can integrate and evolve converters, transformers and connectors independently.
4. SMT (Single Message Transform)
- Optional components that act on the Connect record (schema + value).
- Runs in-memory transformations like:
- Inserting / masking / removing fields
- Changing topic names
- Dropping headers
- Extracting nested fields
- SMTs are stateless and chainable.
- Output: a modified Connect record.
5. Format / Writer (Connector-specific)
- The connector’s sink task / writer takes the transformed Connect record and encodes it into the sink system’s expected format.
- Examples:
- JDBC Sink: maps fields into SQL statements (INSERT, UPSERT, etc.).
- S3 Sink: serializes batches into Parquet/Avro/JSON files.
- Elasticsearch Sink: converts into JSON docs for indexing.
6. Sink System Commit
- The connector pushes the final encoded message to the external system.
- Once successful, it commits offsets back to Kafka.
In next posts I’ll go over some examples of how to use Kafka Connect to ingest data into or out of Kafka.
Comments
Comments are powered by GitHub Issues. If you have a GitHub account, you can leave a comment below!